ИпСЊРібаОПдБШйЛёIEEE Transaction on MultimediaзюЁќМбТлЮФНБ
ЁЁЁЁНќШеЃЌвдЕчзгПЦЁюММДѓбЇЮДРДУНЬхбаОПжааФИпСЊРібаОПдБЮЊЕквЛзїепЕФТлЮФЁЖVideo Captioning with Attention-based LSTM and Semantic ConsistencyЁЗЛёЕУЖрУНЬхСьгђЖЅМЖЦкПЏЁЖIEEE Transaction on MultimediaЁЗЃЈIEEE TMMЃЉдгжО2020ФъзюЈМбТлЮФНБЃЈ2020 Prize Paper AwardЃЉЁЃетЪЧЕчзгПЦММДѓбЇЪзДЮЛёЕУДЫНБЯюЁЃИУТлЮФзїепМАзїепЕЅЮЛЮЊЃКИпСЊРіЃЈЕчзгПЦДѓЃЉЁЂЙљеаЃЈЕчзгПЦДѓЃЉЁЂеХКЌЭћЃЈаТМгЦТФЯЁёбѓРэЙЄДѓбЇЃЉЁЂаьааЃЈЕчзгПЦДѓЃЉЁЂЩъКуЬЮЃЈЕчзгПЦДѓЃЉЁЃ

ЁЁЁЁДДПЏгк1999ФъЕФIEEEЖрУНЬхЛуПЏЪЧЖрУНЬхСьгђзюОпгАЯьСІЕФЖЅЁёМЖЦкПЏЃЌЦкПЏгАЯьвђзг6.051ЁЃIEEE Transaction on MultimediaзюМбТлЮФНБЪЧгЩЙњМЪЖрУНЬхСьгђзЪЩюзЈМвзщЁбГЩЕФIEEE TMMЦРНБЮЏдБЛсЃЌИљІЮОнТлЮФДДаТадЁЂЪЕгУадЁЂЪБаЇадЁЂаДзїБэДяЕШЗНУцЃЌДгЙ§ШЅШ§ФъЗЂБэЕФЫљгаТлЮФжаЭЦМіЦРбЁГіЕФЮЈвЛзюМбТлЮФНБЁЃ

ИпСЊРібаОПдБЕФТлЮФзд2017ФъЗЂБэЈшвдРДЃЌЕУЕНЙњФкЭтЭЌааЙуЗКЙизЂЃЌШыбЁESIИпБЛв§Тл eЮФЃЌЛёGoogleбЇЪѕв§гУ241ДЮЁЃ
ЁЁЁЁИУТлЮФбаОПжїЬтЮЊЪгЦЕУшЪіЩњГЩЃЈVideo CaptioningЃЉЃЌЪєгкМЦЫуЛњЪгОѕКЭздШЛгябдДІРэЕФНЛВцСьгђЃЌФПЕФЪЧЭЈЙ§ЫуЗЈФмЙЛзмНсЪгЦЕЕБжаЗЂЩњЕФвЛаЉЪТЧщЛђепМЧЈТМвЛЯТШЫРрЕФФГаЉаХЯЂЃЌВЂЩњГЩвЛаЉЗћКЯШЫРргябдЙцдђЕФУшЪіЁЃзїепЗЂЯжЃЌЕБЧАЕФДѓЖрЪ§ЗНЗЈЖМЪЧНЋећИіЪгЦЕЕФжЁЛђепЦЌЖЮОљЕШЕУЪфШыЕНЫуЗЈФЃаЭЕБжаЃЌДгЖјКіТдСЫЈKгааЉЪгЦЕжЁЛђепЦЌЖЮЦфЪЕЖдЪгЦЕФкШнЦ№зХжСЙиживЊЕФзїгУЃЌгааЉжЁЛђепЦЌЖЮЖдећИіЪгЦЕЕФгАЯьЮЂКѕЦфЮЂЁЃДЫЭтвЛаЉЗНЗЈЛЙвђЮЊКіТдСЫОфзггявхКЭЪгОѕФкШнжЎМфЕФЯрЙиадЕФЧщПіЃЌЕМжТЗвыДэЮѓЃЌЪгЦЕФкШнКЭЩњГЩОфзгФкШнВЛвЛжТЕФЮЪЬтЁЃ
ЁЁЁЁЮЊСЫНтЁЗОіетИіЮЪЬтЃЌзїепЬсГіСЫвЛИіЛљгкзЂвтСІГЄЖЬЪБМЧвфЭјТчЕФвЛжТадФЃаЭЃЌЫќФмЙЛЗЂОђЪгЦЕЕБжаЯджјЕФвЛаЉЪгЦЕЦЌЖЮРДИЈжњЛёШЁИќМгОпгаДњБэЁћадЕФЪгЦЕФкШнЃЌЭЌЪБЛЙФмЙЙНЈгябдКЭЪгОѕаХЯЂЕФвЛжТадЃЌЪЙЕУЩњГЩЕФОфзггявхКЭЪгЦЕЕБжаЕФгявхБЃГжвЛжТЁЃ
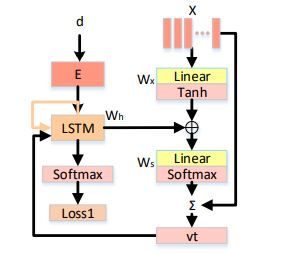
ЁЁЁЁИУЙЄзїЩшМЦСЫвЛжжЛљгкзЂвтСІЛњжЦЕФГЄЖЬЪБМЧвфЕЅдЊЃЌШчЩЯЭМЫљЪОІЦЃЌдкУПвЛДЮНтТыЩњГЩЕЅДЪЕФЪБКђЃЌЛљгкзЂвтСІЕФГЄЖЬЪБМЧвфЕЅдЊЖМЛсИљОнУПвЛжЁЭМЯёЛђепУПвЛИіЦЌЖЮЪгЦЕЕФживЊадИГгшЦфвЛИіШЈжиЃЌзюжеМгШЈжЎКѓЕФЪгОѕЁсЬиеїБЛзїЮЊзюжеЕФЪгОѕБэеїРДАяжњдЄВтЯТвЛИіЕЅДЪЁЃетбљЕФзЂвтСІЕЅдЊФмЙЛАяжњФЃаЭЖЈЮЛОпгаЬиеїБэЪОФмСІЕФЦЌЖЮЃЌИќМгзМШЗЕФЭкОђЕНживЊЕФЪгЦЕФкШнаХЯЂЁЃ
ЁЁЁЁЮЊСЫБЃжЄЩњГЩОфзгКЭЪгЦЕФкШнЕФвЛжТадЃЌГ§СЫЯжгаЕФДгЪгЦЕзЊЛЏЮЊОфзгЕФЫ№ЪЇКЏЪ§ЁЛжЎЭтЃЌИУЙЄзїгжв§ШыСЫвЛИіЪгОѕКЭгябдЕФвЛжТадЫ№ЪЇКЏЪ§ЃЌвдБЃжЄСНепБэДяЕФгявхБЃГжвЛжТЃЌВЛЛсЁўГіЯжгявхЩЯЕФЦЋВюЃЌЭЌЪБДДНЈСЫвЛИіСНжжФЃЬЌЪ§ОнНЛВцЙиСЊЕФгГЩфКЏЪ§ЃЌНЋгябдКЭЪгОѕСНжжФЃЬЌЕФЪ§ОнЭЈЙ§ЯпадБфЛЛгГЩфЕНвЛИіИпЮЌгявхПеМфЃК

ЁЁЁЁЮЊСЫЙЙНЈСНжжФЃЬЌжЎМфЕФЛЅЯрЙиСЊЃЌИУЙЄзїЭЈЙ§вЛИізѓГЫВйзїШЗБЃЭГвЛЪЕР§ЁЧЕФЪгОѕКЭЕЅДЪЬиеїдкAПеМфжавЛжТЃК
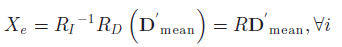
ЁЁЁЁЦфжаЃЌ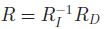
ЁЁЁЁвђДЫФмЙЛЭЈЙ§зюаЁЛЏгявхЯрЙиЖШЕФЖўЗЖЪ§ЕУЗжЃЌБЃжЄЩњГЩЕФЕЅДЪгыЪгЦЕЪгОѕЩЯЯТЮФжЎМфЕФгяЈвхвЛжТадЃЌЪЙОфзгОпгаЗсИЛЕФгявхЩЯЯТЮФаХЯЂЁЃ
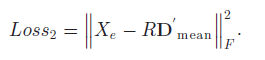
ЁЁЁЁдкЪЕбщбщжЄНзЖЮЃЌЙЄзїзщЗжБ№ВтЪдСЫГЄЖЬЪБМЧвфЪгОѕБрТыФЃПщКЭгявхвЛжТадФЃПщдкФЃаЭЕБжаЕФОпЬхаЇЙћЃЌЪЕбщНсЙћШчЯТБэЫљЪОЃК

ЁЁЁЁФмЙЛПДГіСНепЖдгкЈvзюжеФЃаЭЖМгаЗЧГЃДѓЕФЙБЯзЃЌСНепвВЪЧШБвЛВЛПЩЁЃ
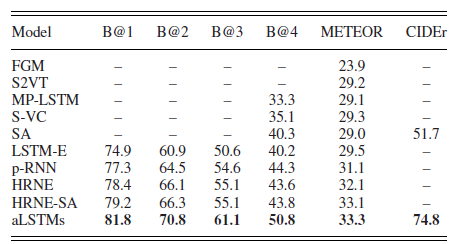
ЁЁЁЁзїепНЋИУЙЄзїФЃаЭНсЙћКЭЕБЪБзюКУЕФвЛаЉЗНЗЈЕФЁўНсЙћНјааСЫБШНЯЃЌДгMSVDЪ§ОнМЏЕФЪЕбщНсЙћРДПДЃЌИУЙЄзїФЃаЭдкИїЯюжИБъжаЖМШЁЕУСЫЕБЪБзюКУЕФНсЙћЃЌетвВбщжЄСЫФЃаЭЕФгааЇадЁЃ

ЁЁЁЁГ§ІЮЁЁСЫСПЛЏжИБъжЎЭтЃЌТлЮФзїепЛЙеЙЪОСЫвЛаЉФЃаЭЩњГЩОфзг eЕФвЛаЉНсЙћЃЌЭМжаSAБэЪОЕФЪЧsoft attentionЗНЗЈЃЌGTБэЪОЕФЪЧgroundtruthЃЌЪЧШЫРреыЖдетаЉЪгЦЕЪ§ОнНјааЕФБъзЂЁЃДгетИіПЩЪгЛЏЭМРДПДЕФЛАЃЌЪзЯШБэЪОСЫИУЙЄзїдіМгЕФгявхвЛжТадЫМЯыЪЧгааЇЕФЃЌЫќФмЩњГЩИќМгЁёзМШЗЕФОфзгУшЪіЃЌФмИќМгзМШЗЕФАбЮеЪгЦЕЕБжаЕФЙиМќаХЯЂЃЌР§ШчЁАroadЁБЃЌЁАsingingЁБЕШЖЏзїЁЃКЭЦфЫћЕФЗНЗЈЯрБШЕФЛАЫќЕФдЄВтвВИќМгзМШЗЃЌИќМгНгНќШЫРрЕФгябдУшЪіЯАЙпЁЃ
ЁЁЁЁЯрЙиСДНгЃК
ЁЁЁЁИпСЊРібаОПдБРлМЦЗЂБэИпЫЎЦНЙњМЪТлЮФ100грЦЊЃЈвЛзї/ЭЈбЖ53ЦЊЃЉЃЌGoogle Scholarв§гУ2289ДЮЁЃдкЙњМЪЖЅМЖЦкПЏЈКЭЛсвщЃЈШчCCF AРрЛсвщЁЂIEEE/ACMЛуПЏЕШЃЉЩЯЗЂБэТлЮФЙВМЦ50грЦЊЃЌШчIEEE T-PAMIЁЂIJCVЁЂ IEEE T-IPЁЂ IEEE T-MMЁЂCVPRЁЂACM MultimediaЁЂAAAI/IJCAIЕШЁЃЦфжаШыбЁESIИпБЛв§ТлЮФ4ЦЊЃЈвЛзї/ЭЈаХЃЉЃЌВЂЛёЕУIEEE TMMзюМбТлЮФНБЁЂЙњМЪЛсвщADCзюМббЇЩњТлЮФНБЁЃжїГжЖрЯюЙњМвМЖКЭЪЁВПМЖЯюФПЃЌжїбаЙњМвПЦІЗ ММВПжиЕуЯюФПвЛЯюЃЌздШЛПЦбЇЛљН№УцЩЯЯюФПвЛЯюЕШЁЃдјЕЃШЮCCF-BЛсвщЕФISWCбаЬжЛсЕФГЬађЮЏдБЛсжїЯЏЃЌSCIЦкПЏJCVIRЬиПЏЕФПЭзљБрЮЏЃЌAPWEB-WAIMЛсвщбаЬжЛс(workshop)жїЯЏ(chair)ЕШбЇЈ|ЪѕМцжАЃЌвдМАЕЃШЮCCFЭЦМіЕФЖрИіЛсвщКЭЦкПЏЕФЩѓИхЈШЫЁЃЛё2019ФъАЂЁбРяАЭАЭЁАДяФІдКЧрГШНБЁБЃЈШЋЙњНі10УћЃЉЃЌ2020ФъIEEE TCMCбЇЪѕаТаЧНБ(Rising Star Award)ЃЌШыбЁ2020ФъЫФДЈЪЁЁАШ§АЫКьЦьЪжЁБЁЃ
ЮДОдЪаэВЛЕУзЊдиЃКЖўОХФъЛЊДѓбЇУХЛЇ » ИпСЊРібаОПдБШйЛёIEEE Transaction on MultimediaзюМбТлЮФНБ
ЯрЙиЭЦМі
- ЭѕжОУїНЬЪкЭХЖгдкЁОЁЖAccounts of Chemical ResearchЁЗЗЂБэЗтУцТлЂйЮФ
- ЬЋЛнСсНЬЪкШйЛёЁАЪЎМбЫФЁїДЈЪЁЮхвЛНэрўБъБјЁБШйгўГЦКХ
- вЫБіЪаЮЏЪщМЧСѕжаВЎЁ№вЛааРДаЃЗУЮЪ
- ЕчзгБЁФЄгыЁћМЏГЩЦїМўЙњМвжиЕуЪЕбщЪвбЇЪѕЮЏдБЛсейПЊФъЛс
- ЫФДЈЪЁЕквЛЗтИпПМТМШЁЭЈжЊЪщДгЕчзгПЦДѓЗЂГі
- ГіАцІцЩчВЮМгЪзНьЁАЬьИЎЪщеЙЁБ4ГЁЛюЖЏеЙЪОЮФЛЏздЁёаХ
- ОЙмбЇдКгыЕчзгПЦДѓЁМГіАцЩчбаЬжГіАцКЯзї
- бЇЙЄВПОйааИЈЕМдБЙЄзїЪвД№БчЛс
- ЕкШ§НьаТЫФЛсФмСІЬєеНШќОЋВЪЩЯбн
- ЕкЫФНьЕчзгПЦММДѓбЇЁАЛЅСЊЭј+ЁББОПЦНЬг§ИпЗхТлЬГПЊФЛ
- АЎЖћРМзЄЁшЛЊДѓЪЙРюаоЮФвЛааРДаЃЗУЮЪ
- ЫФДЈЪЁЮЏЪщМЧХэЧхЛЊРДаЃЕїба
- ЕчзгПЦДѓгыЙњЭјЫФДЈЪЁЕчСІЙЋЫОЙВНЈЗКдкЕчСІЮяСЊЭјСЊКЯбаОПдК
- ШчЦкПЊПЮЪзЈ}ШеЃЌЭѕбЧЗЧЪщМЧгыЪІЩњвЛЦ№дкЯпЩЯПЮ
- ЙЋЙВЙмРэбЇдКОйАьЁАЭђРяаЧКгЃЌЧвУЮЧвИшЁЊЧыЛиД№2020ЁБгаТЭэЛс
- бЇаЃЕГЁіЮЏРэТлбЇЯАжааФзщОЭЁАПЦММБЈЙњЕЃЪЙУќЃЌЗмСІНЈЩшЁЎЫЋвЛСїЁЏЁБНјааМЏжабЇЯА
- ЕчзгПЦЈДѓЕЫаёНЬЪкЭХЖгдкNatureЗЂБэЗтУцТлЮФ
- зЪЛЗбЇдКОйаа2019ФъЁАзЪвтЩњГЄЃЌЧрДКЗЩбяЁББэеУДѓЛсєпгаТЭэЛс
- ЁОПЙЛїаТЙкЗЮбзЁПЛЦЯўВЈЃКДјВЁдЎЖѕЃЌЗмСІеНЁАвпЁБЃЁ
- ЁОУРРіГЩЕчЁЄЗюЯзжЎУРЁПВЗЗВЃКШУИќЖрШЫПьРжВХИќгавтвх
аТЮХЙЋИц
ИпПМеаЩњ
- ИёРЫЙИчбЇдК2015еаЩњМђеТ 08-05
бЇаЃРЯЪІ
- РМИе
- ЖХГЩАВ
- ЛЦЯўИя
- ГЩаЂгш
- ЛЦПЫОќ
- ИпМб
- СѕМгСж
- ЮтЮРШК
- КњРшРш
- жьЮЌРж
- еХгГУє
- РюгРБђ
- ГТДКбр
- РзСи
- ШФНЈеф
- РюШ№
- зцаЁЬЮ
- ТэвхВХ
- еХдЦЖљ
- ЖЮЯўРт
- ЮтЮАЯМ
- ГТЙтгю
- НЏЯўФШ
- еХН№Йѓ
- дЌДЋЛГ
- РюЙњЛЏ
- аэДКЧр
- ТэаЁИе
- ЬяОЖ
- ЪЗДЈОќ
- ёћЫМвх
- жмфьгъ
- аэжЎ
- СшЯш
- РюЛнШи
- едЫЋ
- МжгёЫЋ
- ГТвй
- РюН№Сс
- РюгёАи
- КЮаЫИп
- ЮтЛД
- аЛОќ
- гїЮА
- ЮКНЈУї
- РюдѓКъ
- ЮтдЦЗх
- КиЬЮ
- Сѕбр(Этгя)
- еХгЅ